Practical Approach for idenitfying Transactional Anomalies
Motivation:
In this guide, you’ll learn how to get started with Anomaly Detection using Python, including:
What is Anamoly?
What are the challenges of Traditional methods to do Anamoly?
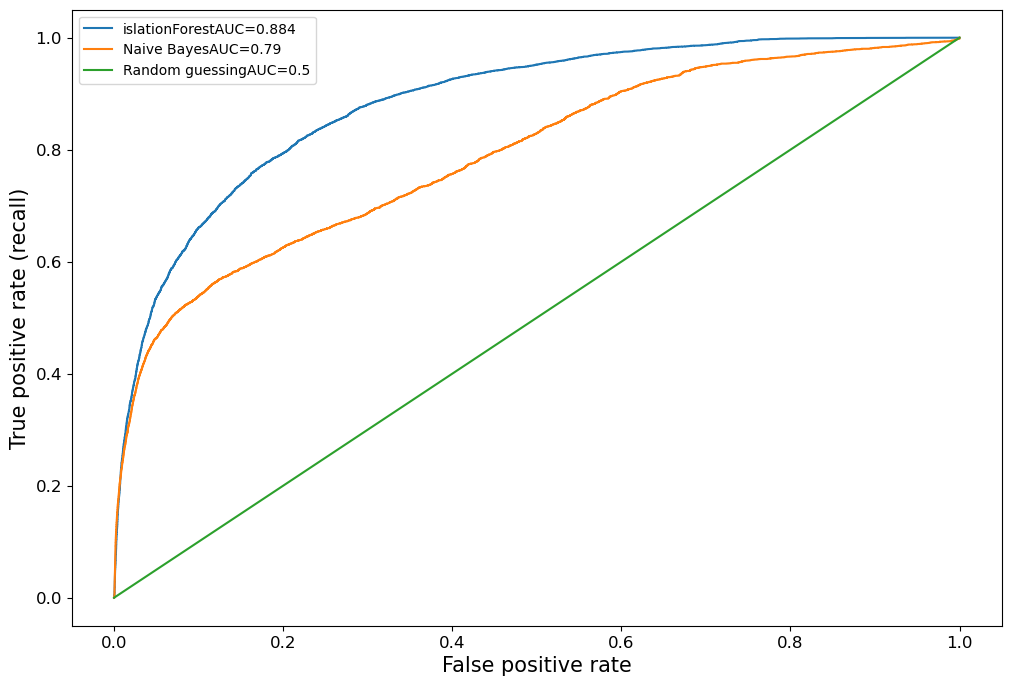
Using Isolation Forest for Anamoly Detection.
How to explain the results?
Problem and Requirements:
In finance Such as Banking , Ecommerce some users perform illegal transactions in the database and those transactions leave records in database. How ever this database is mostly composed of non criminal transactions from the people who comply with the rules of the system they are part of.
Goal: To identify this Fraudulant Transactions by means of running our Database through Anamoly detection system.
Good news: Our database has all the records for idenitfy the crime.No need for data gathering.
Bad news: Fraudlent transactions of the data is buried in millions of records and you might not recognise fradualnt transaction in the records.
Challenges:
Need for automation mainly because the sheer size of the records make the manual validation of the data to identify the anomaly is impossible to check all records.
If the problem is that the human expersts dont have the time to go through the dataset can we try to automate their decision process?
Rule Based approach - If experts could complie a set of rules for instance transactions that exceed a certain amount are anomaly or transactions of certain type X at certain time Y are considered anolmaly etc. Any type of clearly defined rule to singleout a fradualant transaction. With this rule we can easily implement a system that can easily flag any anamolous transaction.that fullfill the rules of anamoly.
How ever they are several problems with this approach. Coming up with a good set of rules require a lot of expertise and work rule needs to be validated and for particular dataset at hand.
If the dataset format changes or a different dataset is used with different distribution the complete set of rules need to be reworked to reflect the new situation.
Finally and most importantly its impossible to predict to all shapes and forms that anomalies can assume.
Solution to the above challenge: To address this problem of unknown nature of fraudulent transactions we can make use of data we have in the database. We have to build a system which learns from the data what constitues an anomly.
We have to put the requirement that the model has to be unsupervised meaning that when we train this model we will not be able to tell that which are anamoly or not. we dont have any information on that so far.
Machine Learning approach: first step we train a unsupervised model on our data to learn about
First step we train a unsupervised model on our data to learn about distribution of data and to get a sense of what an anamoly is in our context.
In step two we use this model to predict the likelihood of a transaction being fraud for every transaction using what it has learned in the above step.
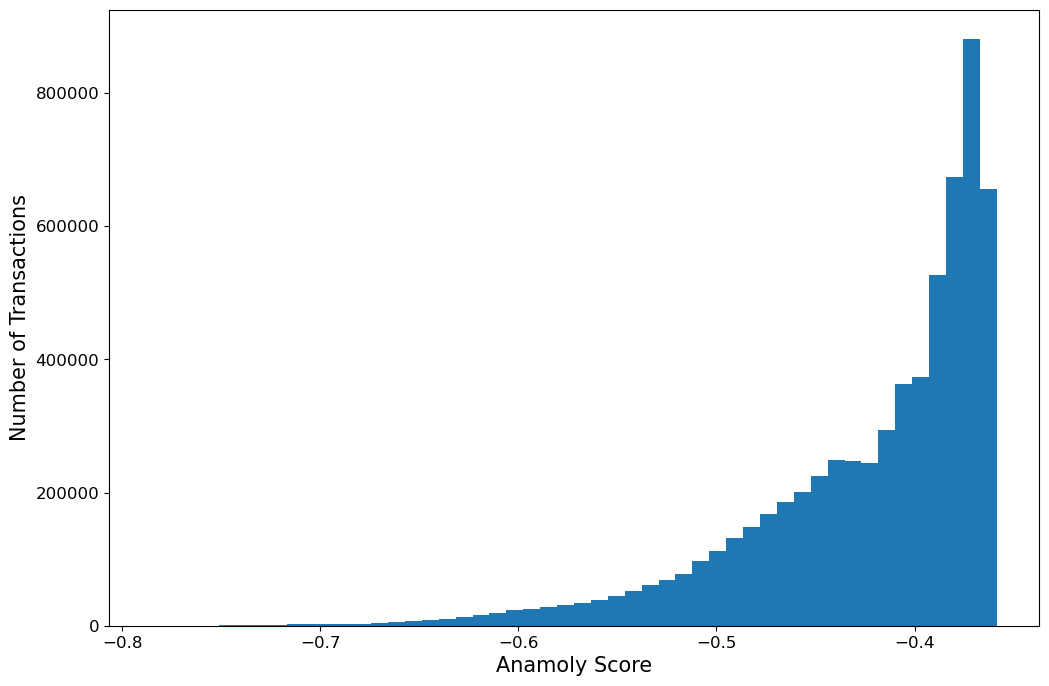
A machine learning model will never give a definitive answer of whether a transaction is anamoly their will be always an inheriant uncertanity in the answers it give us. If our model gives a continous value as anamoly score that refelcts the model certanity of the transaction likely to be anamoly we can choose ourself how wide we want to cast our net while looking for possible anamoly.
The output of the model will be a mapping of every transaction to certain a anamoly score. This score reflects how certain our model is of certain transaction as anamoly or not. If we want to consider some subset of transaction we have to set a threshold. the nature of anamoly will help us to consider how wider net we want to perform . Downside is we might not undestand why a transaction is anamoly .thats why we have explanability to the model to understand why model has flagged a certain transaction as anamoly.
Dataset:
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.ensemble import IsolationForestfrom sklearn.metrics import f1_score, precision_score, recall_score, roc_curvefrom sklearn.metrics import plot_precision_recall_curve, precision_recall_curve, roc_auc_scorefrom tqdm import tqdmimport shapshap.initjs()plt.rcParams["figure.figsize"] = (12,8)
data = pd.read_csv(r'C:\Users\MY\Desktop\Blogs\Fraud_Detection_Blog\PS_20174392719_1491204439457_log.csv')
data.head()
step
type
amount
nameOrig
oldbalanceOrg
newbalanceOrig
nameDest
oldbalanceDest
newbalanceDest
isFraud
isFlaggedFraud
0
1
PAYMENT
9839.64
C1231006815
170136.0
160296.36
M1979787155
0.0
0.0
0
0
1
1
PAYMENT
1864.28
C1666544295
21249.0
19384.72
M2044282225
0.0
0.0
0
0
2
1
TRANSFER
181.00
C1305486145
181.0
0.00
C553264065
0.0
0.0
1
0
3
1
CASH_OUT
181.00
C840083671
181.0
0.00
C38997010
21182.0
0.0
1
0
4
1
PAYMENT
11668.14
C2048537720
41554.0
29885.86
M1230701703
0.0
0.0
0
0
About Data: step - maps a unit of time in the real world. In this case 1 step is 1 hour of time. Total steps 744 (30 days simulation). type - CASH-IN, CASH-OUT, DEBIT, PAYMENT and TRANSFER.
amount - amount of the transaction in local currency.
nameOrig - customer who started the transaction
oldbalanceOrg - initial balance before the transaction
newbalanceOrig - new balance after the transaction
nameDest - customer who is the recipient of the transaction
oldbalanceDest - initial balance recipient before the transaction. Note that there is not information for customers that start with M (Merchants).
newbalanceDest - new balance recipient after the transaction. Note that there is not information for customers that start with M (Merchants).
isFraud - This is the transactions made by the fraudulent agents inside the simulation. In this specific dataset the fraudulent behavior of the agents aims to profit by taking control or customers accounts and try to empty the funds by transferring to another account and then cashing out of the system.
isFlaggedFraud - The business model aims to control massive transfers from one account to another and flags illegal attempts. An illegal attempt in this dataset is an attempt to transfer more than 200.000 in a single transaction.
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another
user you must also trust this notebook (File -> Trust notebook). If you are viewing
this notebook on github the Javascript has been stripped for security. If you are using
JupyterLab this error is because a JupyterLab extension has not yet been written.
The above plot shows how the individual features of the data point contributed to shifting the model output from its expected to base value. These contributing values are called SHAP values. Blue values are contributing to lower the anamoly score and the red values for higher anamoly score.
For the above entry features such as amount(higher amount) is suggestive that the data is anamolous.
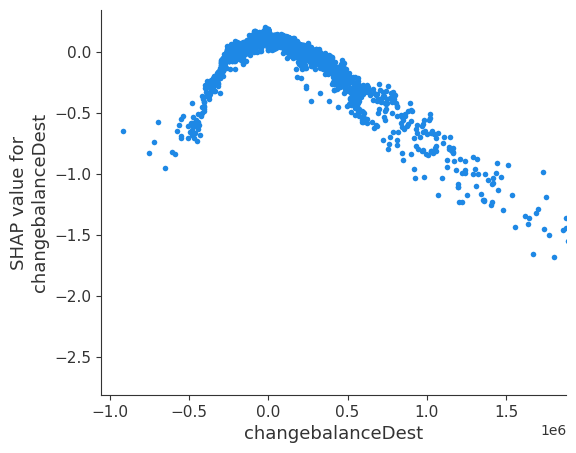
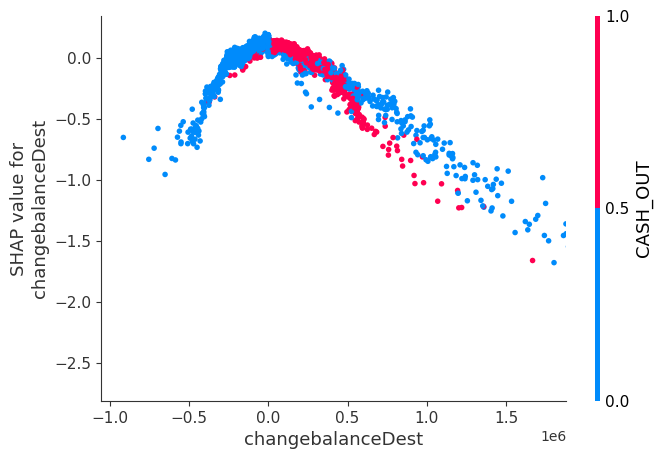
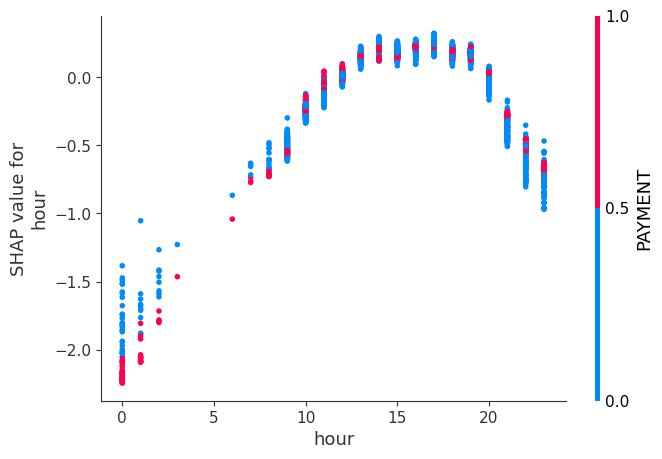
SHAP values are local explanations of different features for a given data point. To gain the global trends by aggregating the local explanations.
SHAP library has a library called dependence plot which shows us how mulitple datapoints of shap value depend on the feature .
The above guide demonstrates how to get started with Anomaly Detection using Python and the Isolation Forest algorithm. The guide explains the challenges of traditional methods for anomaly detection, such as rule-based approaches, and provides a solution to these challenges by using a machine learning approach. The guide uses the Isolation Forest algorithm to train a model on the data and predict the likelihood of a transaction being fraudulent based on the learned information. The guide also explains how to evaluate the results and provides code for visualizing the results using SHAP. The conclusion of the guide is that using a machine learning approach, specifically the Isolation Forest algorithm, can effectively identify fraudulent transactions in large datasets and provide a certain level of certainty in its predictions.